JS 作用域
this 的不同应用场景
什么是 this
this 是执行上下文的一个属性,执行上下文是函数在被调用时创建的活动记录,包含函数调用的位置(调用栈)、调用方式、传入参数等信息,而 this 就是其中的一个属性,在函数执行时会使用,所以 this 的取值(指向)是在函数执行时确定的;
严格的说,调用栈包含调用位置,调用栈也可以称作调用链,是指为了到达当前执行位置所经过(调用)的所有函数,而调用位置只是当前执行函数的前一个调用;
调用栈
栈是一种数据结构,规则是“First-In-Last-Out”,JS 在调用函数前,会把函数所需的环境压入栈顶,等函数执行完毕,就会把环境弹出,然后返回上一个执行上下文,继续向下执行,这样一层一层的入栈、执行、返回就可以称为调用栈;
概念很抽象,要想看到调用栈,方法很多,这里说一下常见的两种方法:
示例代码 👇 来自《你不知道的 JavaScript 上卷》第二部分第 2 章;
1 | function fn1() { |
触发一个错误;
![触发一个错误]()
触发错误后,可以清晰的看到调用栈的情况,请注意,调用栈是自下向上的;
在代码中添加
debugger;:![debugger]()
运行到
debugger;时,浏览器的调试器会中断,同时展示当前位置的函数的调用列表,这就是调用栈;
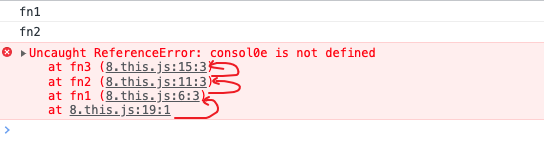
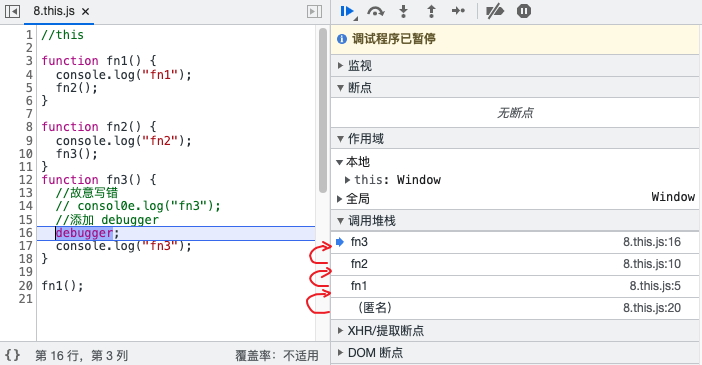
无论通过何种方法得到调用栈,栈中的第 2 个元素(自上向下)就是真正的调用位置;
this 的绑定规则
- 普通函数调用,严格模式绑定到 undefined,宽松模式绑定到 window;
- 对象方法调用,绑定当前对象;
- class 方法调用,绑定到实例对象;
- call, bind, apply 绑定到指定对象(传入的对象);
- 箭头函数,绑定到上级作用域的 this;
手写 bind 函数
提到 bind 就不得不提 call 和 apply,它们三个都可以改变函数的上下文,也就是 this 的指向;
bind、call、apply 的区别
- call 和 apply 会使用调用者提供的 this 和参数,立即调用函数,并返回函数调用的结果,如果调用者没有返回值,则返回 undefined;
- bind 会使用调用者提供的 this 和参数,返回一个新函数,新函数的 this 就是调用者提供的 this,而其余的参数则作为新函数的参数,供新函数被调用时使用;
- apply 只能有两个参数,第 1 个是提供的 this,第二个是数组或类数组对象形式的参数列表;
- bind 和 call 可以有多个参数,第 1 个参数和 apply 一样,都是提供的 this,其余的是参数列表;
手写 new 操作符
bind 方法返回一个函数,理所当然能被 new 操作符调用,所以手写 bind 方法前,需要了解 new 操作符;
new 操作符的做了什么?看看MDN的描述:
- 创建一个空的简单 javascript 对象;
- 为这个空对象添加
__proto__属性,并将该属性链接至构造函数的原型对象; - 将这个空对象作为上下文的 this;
- 运行传入的函数,如果该函数没有返回值,则返回 this;
1 | function myNew(fn, ...args) { |
手写 bind
语法function.bind(thisArg[, arg1[, arg2[, ...]]])
1 | //1. 首先是只有函数才能调用 bind,所以需要定义在 Function.prototype 上,再一个就是不能和原生方法同名 |
使用测试
1 | let name = "global_name"; |
支持 new 操作符
1 | Function.prototype.myBind = function (context, ...params) { |
手写 call
语法function.call(thisArg, arg1, arg2, ...)
要求:
- 不传入第 1 参数,上下文默认为 window
- 改变 this 指向新对象,新对象可以执行函数,并且可以接收参数
1 | //1. call 只能由函数调用,同时还要防止覆盖原生方法 |
使用测试
1 | window.name = "global_name"; |
手写 apply
apply 和 call 类似,唯一的不同在于 apply 要求参数列表是数组或类数组;
但有了扩展运算符...后,它俩可以完全相同;
1 | // 与 call 一样,apply 同样只能由函数调用,同时还要防止覆盖原生方法 |
闭包
引用《你不知道的 JavaScript 上卷》第一部分第 5 章对闭包的定义:
当函数可以记住并访问所在的词法作用域,即使函数是在当前词法作用域之外执行,这时就产生了闭包。
这句话好理解又不好理解:
因为
当函数可以记住并访问所在的词法作用域后面使用了即使,所以可以理解为有另外一种情况,函数没有在当前词法作用域之外执行,经典的代表就是 IIFE(立即执行表达式) 模式;1
2
3
4var a = 2;
(function IIFE() {
console.log(a);
})();这段代码来自书中,同时作者认为这不是闭包,因为函数是在它定义时所在的作用域中执行的,而其中的 a 是通过普通的词法作用域查找而非被闭包发现的;
但单纯从代码层面来看,它确实产生了闭包的效果;
先说说个人理解,当函数不是在定义的作用域执行,但却可以记住并访问定义时的作用域,就是闭包;
私以为下面这句话对闭包的描述更贴切:
存在自由变量的函数就是闭包;
真的很精练,越品越贴切;
常见的闭包
- 函数作为参数被传递
- 函数作为返回值被返回
例 1,IIFE:
1 | var a = 20; |
例 2,函数作为返回值:
1 | function fn1() { |
例 3,函数作为参数:
1 | function fn1(fn) { |
结果是否如你所愿?这里就要引入自由变量;
自由变量
自由变量就是当前作用域未定义但被使用了的变量;
所有自由变量的查找,是在函数定义的位置向上查找,而不是在执行的位置;
看完自由变量的定义及查找规则,是否对上面的例子有了不同的理解?
作用域
要谈闭包就不得不提作用域;
作用域就是变量的合法使用范围;
作用域又分为:
- 全局作用域:任何位置都可以访问;
- 函数作用域:函数内部的任何位置可以访问;
- 块级作用域:任何含有大括号(
{})的代码块,需要配合 let、const 一起使用,如 for、if、try…catch 等或独立的{};
闭包的使用场景
防抖和节流
防抖:对于频繁触发的事件,在事件触发停止后的指定时间后进行响应,在此时间内如果继续触发,则重置时间,直到停止触发时间达到设定时间,然后进行响应;
1 | function debounce(fn, delay) { |
节流:对于频繁触发的事件,指定时间内只执行一次;
1 | function throttle(fn, delay) { |
私有方法和变量(属性)- 隐藏内部实现
1 | // 缓存函数 |
构建命名空间 - 规避变量名冲突
1 | let a = 10; |
函数柯里化
Currying - 只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
先来道开胃小菜 👇:
1 | // 柯里化求和函数 |
很简单吧,再来看一道经典的题目 👇:
1 | // 实现一个add方法,使计算结果能够满足如下预期: |
先不看第 3 个要求,前两个都是 4 个参数,由易到难实现一下:
1 | function add() { |
结果如下:
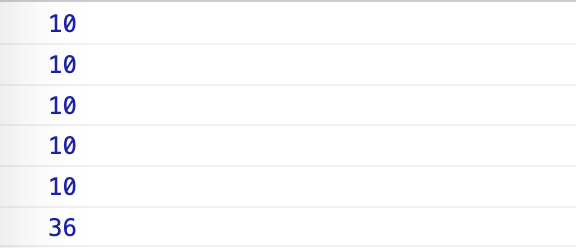
嗯,看着很 OK,甚至还能满足console.log(add(1, 2, 3, 4, 5, 6, 7, 8));这种不限参数的调用,但也只能这么调用,不能像题目中第 3 个要求那样柯里化调用;
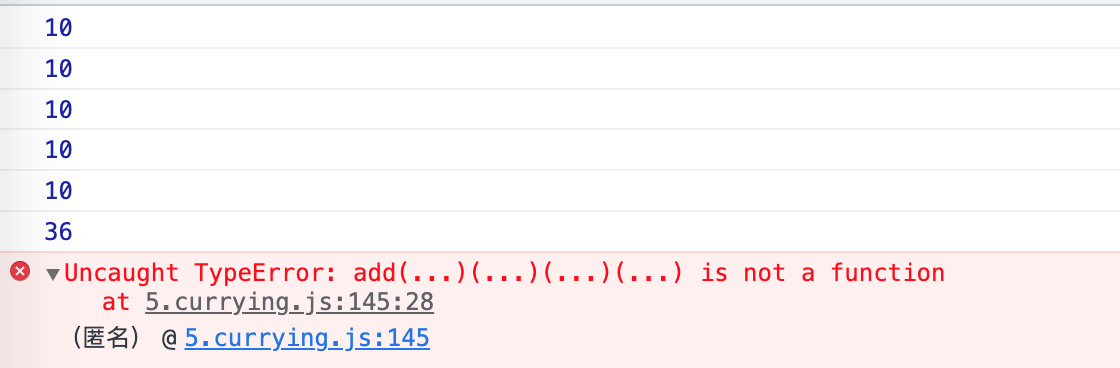
出错的原因在于 add 中参数限制为 4 个,然后就返回它们的和了,对一个数字进行函数调用当然会出错;
如何能让函数自己判断参数的结尾呢?延迟执行,何为延迟执行,就是在使用函数时,手动通知函数,参数传完了,返回结果吧;
暂停好奇心,先来完善一下上面的代码,不能每次参数的数量变了就改函数的参数吧,这次是 4,下次是 5,下下次是 6 呢?
1 | function toCurry(fn) { |
解释一下代码中的??,为啥不用return fn.apply(fn, args);而是弯弯绕先存储结果然后清空args呢?因为args的作用域在 toCurry 函数内,每次计算结束后如果不清空,上一次的参数会保留下来作为下一次的计算参数,这可就出问题了;
测试一下:
1 | function add(a, b, c) { |
结果如下:
优化一下弯弯绕:
1 | function toCurry(fn) { |
可以再优雅一点:
1 | function toCurry(fn) { |
现在来说一说上面提到的延迟执行:累积传入的参数,在没有参数时执行;
1 | function add() { |
提取通用函数:
1 | function toCurry(fn) { |
结果如下:
柯里化的应用场景
延迟执行,上面已经说过了;
参数复用,
正则表达式验证字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21function check(reg, str) {
return reg.test(str);
}
console.log(check(/\d+/g, "hello")); // false
console.log(check(/[a-z]+/g, "hello")); // true
function toCurry(reg) {
return function (str) {
return reg.test(str);
};
}
let hasNumber = toCurry(/\d+/g);
let hasString = toCurry(/[a-z]+/g);
// 复用
console.log(hasNumber("hello")); // false
console.log(hasNumber("hello1")); // true
console.log(hasString("hello")); // true
console.log(hasString("hello1")); // false惰性载入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26function addEvent() {
if (document.addEventListener) {
addEvent = function (element, event, handler, capture) {
element.addEventListener(event, handler, capture);
};
} else if (document.attachEvent) {
addEvent = function (element, event, handler, capture) {
element.attachEvent("on" + event, handler);
};
} else {
addEvent = function (element, event, handler, capture) {
element["on" + event] = handler;
};
}
return addEvent.apply(this, arguments);
}
// 使用
addEvent(
window,
"DOMContentLoaded",
function () {
alert("hello");
},
false
);
闭包的特性
- 封闭性:外界无法访问闭包内部的数据,如果在闭包内声明变量,外界是无法访问的,除非闭包主动向外界提供访问接口,也就是私有化属性和方法以及命名空间;
- 持久性:一般的函数,调用完毕之后,系统会自动销毁函数,而对于闭包来说,在外部函数被调用之后,闭包结构依然保存在系统中,闭包中的数据依然存在,从而实现对数据的持久使用,柯里化就是典型应用;
闭包的优缺点
优点:
- 减少全局变量,避免命名冲突;
- 减少函数的传参量;
- 封装,私有成员;
缺点:
- 常驻内存,增加内存使用量;
- 使用不当会很容易造成内存泄露;
使用闭包的注意点
- 减少使用闭包,用别的方法替代;
- 退出函数前,将局部变量删除;