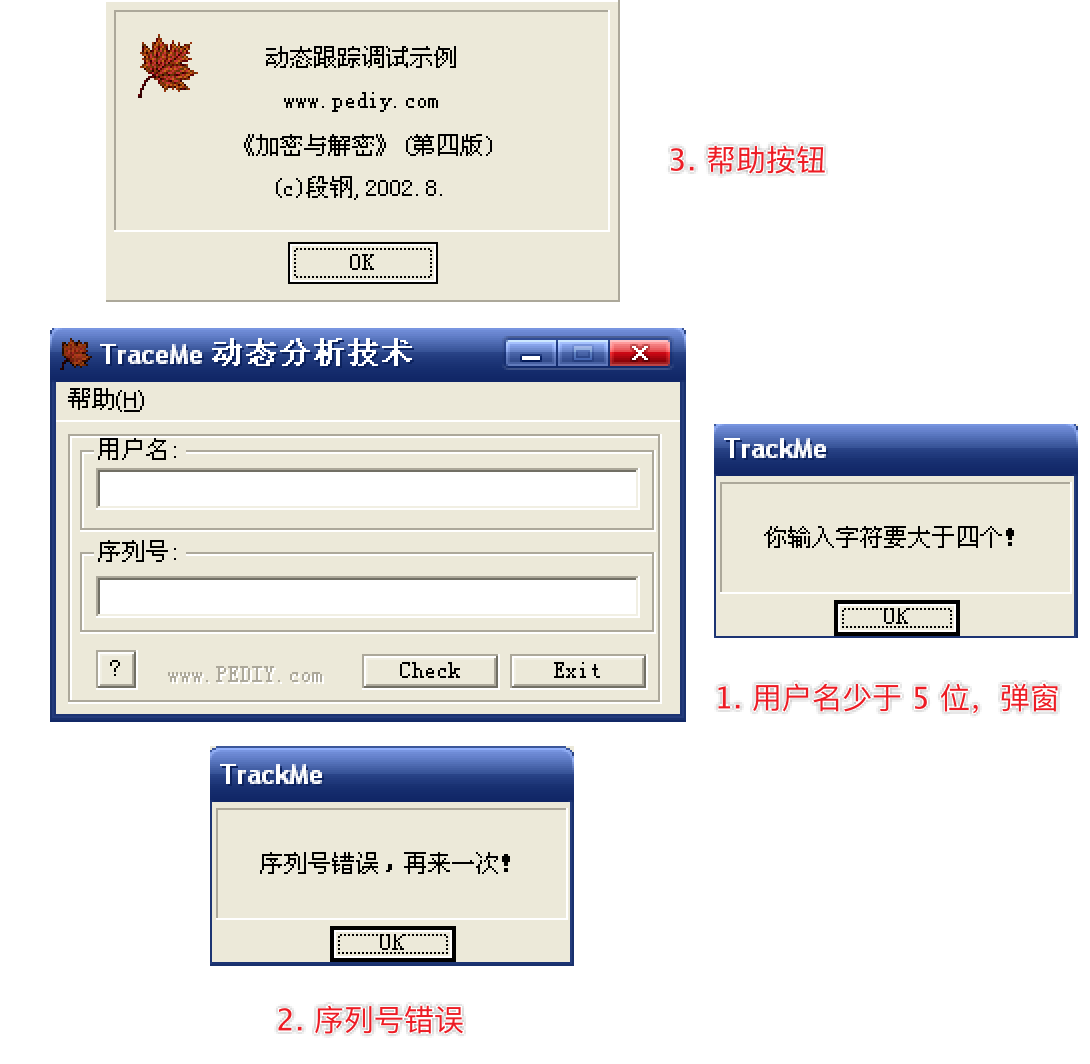
软编码寻找序列号(四)
使用工具
- OllyDbg 1.10原版,简称
OD; OD汉化和插件均来自互联网;- CrackMe来自互联网,仅供学习使用;
- 文中特殊数字均是
HEX,为了书写方便采用DEC;
分析思路
首先运行程序,梳理程序流程:
![梳理程序流程]()
- 用户名不能少于 5 位(也就是提示的大于 4 位);
- 既然用户名是随机的,注册码应该是根据用户名动态生成的;
- 有弹窗,可以试试
MessageBox; - CM 来自加密解密,段钢大佬的作品,翻阅加密解密还真有这个示例以及分析思路;
- 不过,先不看书中的分析思路,自己分析,然后和大佬的分析做比对,看看自己有什么疏漏;
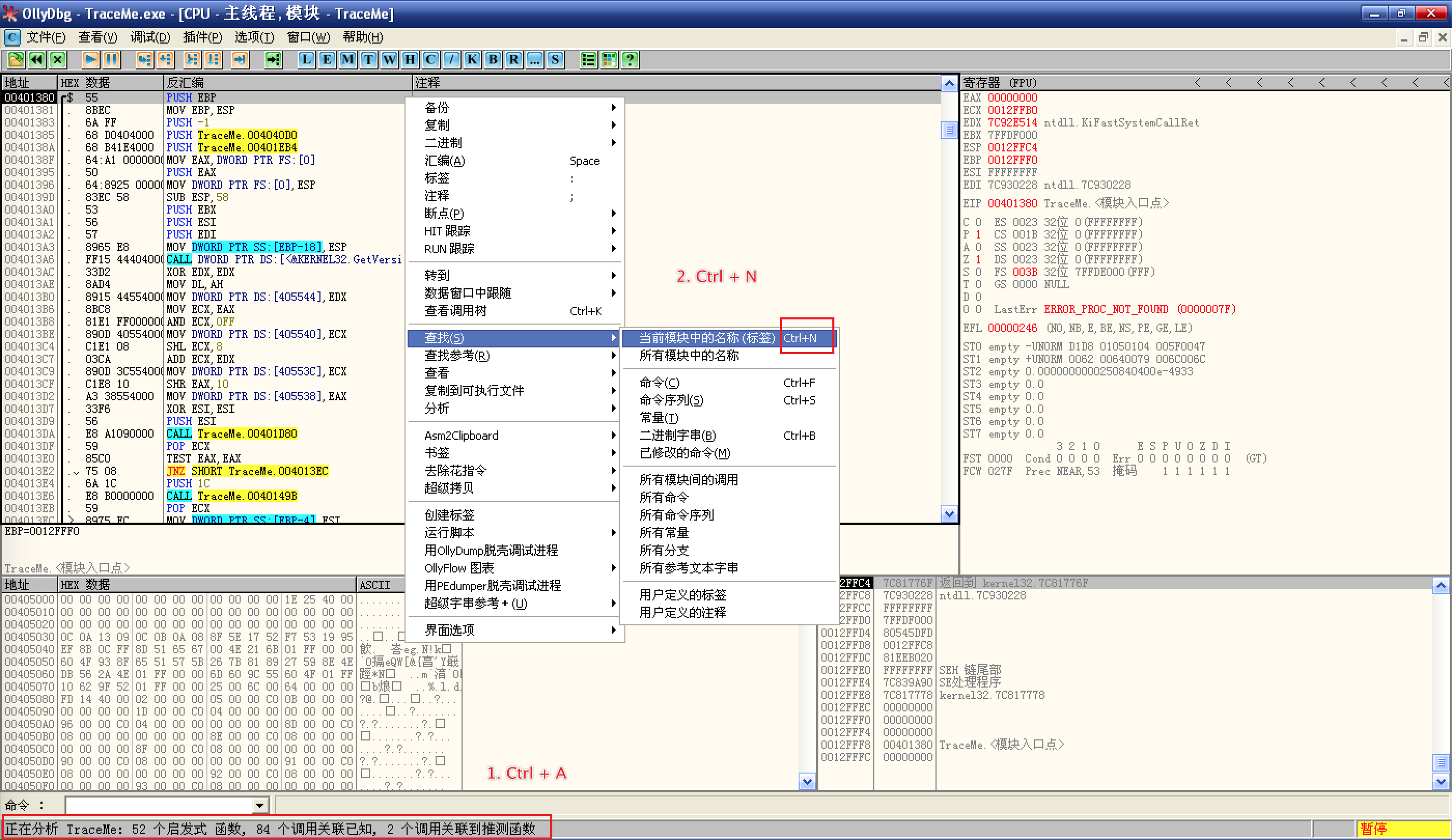
将 CM 导入 OD,先 Ctrl + A 让 OD 自动分析一下 CM,然后 Ctrl + N 查找当前模块中的名称:
![Ctrl + A]()
![Ctrl + N]()
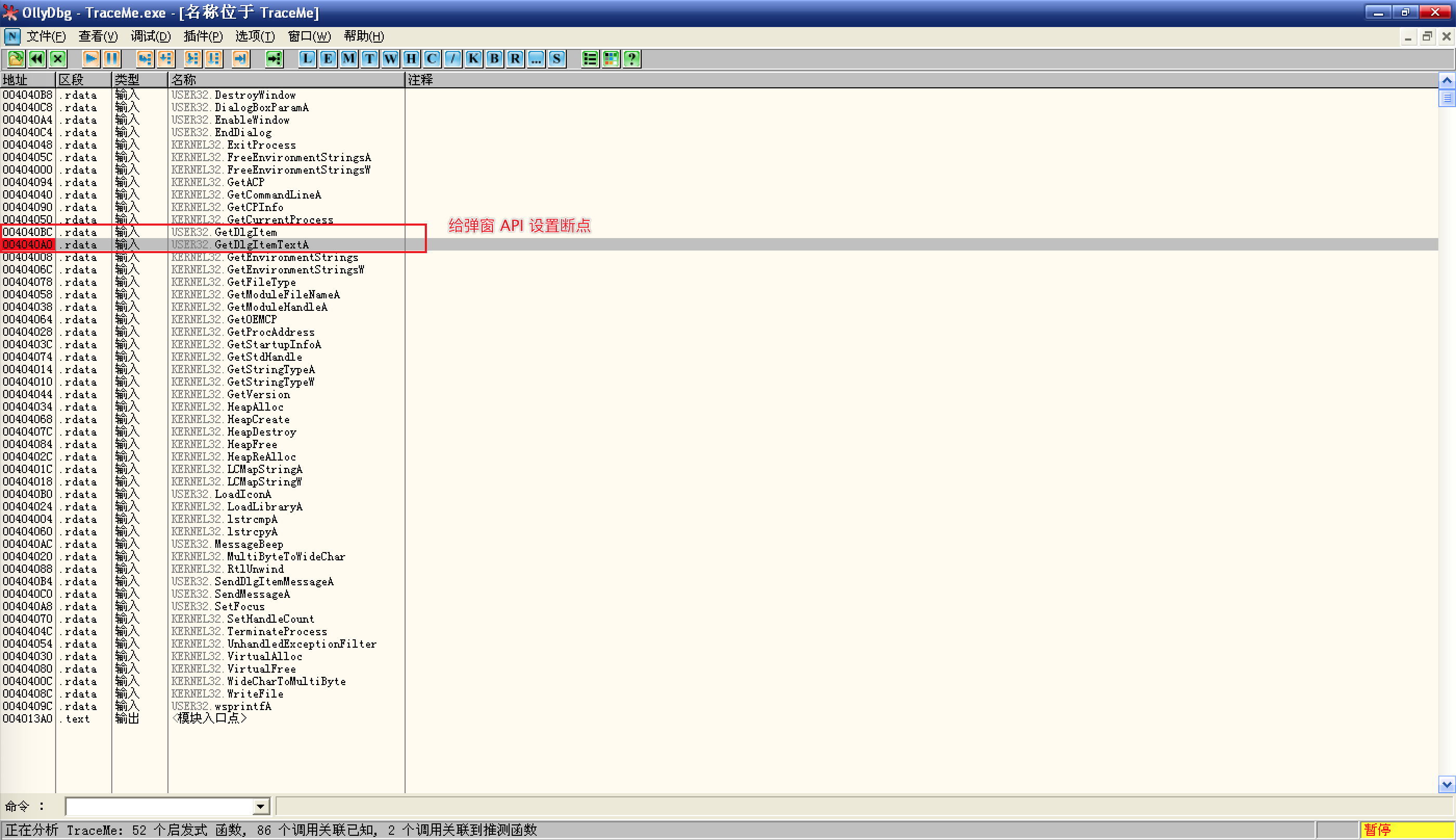
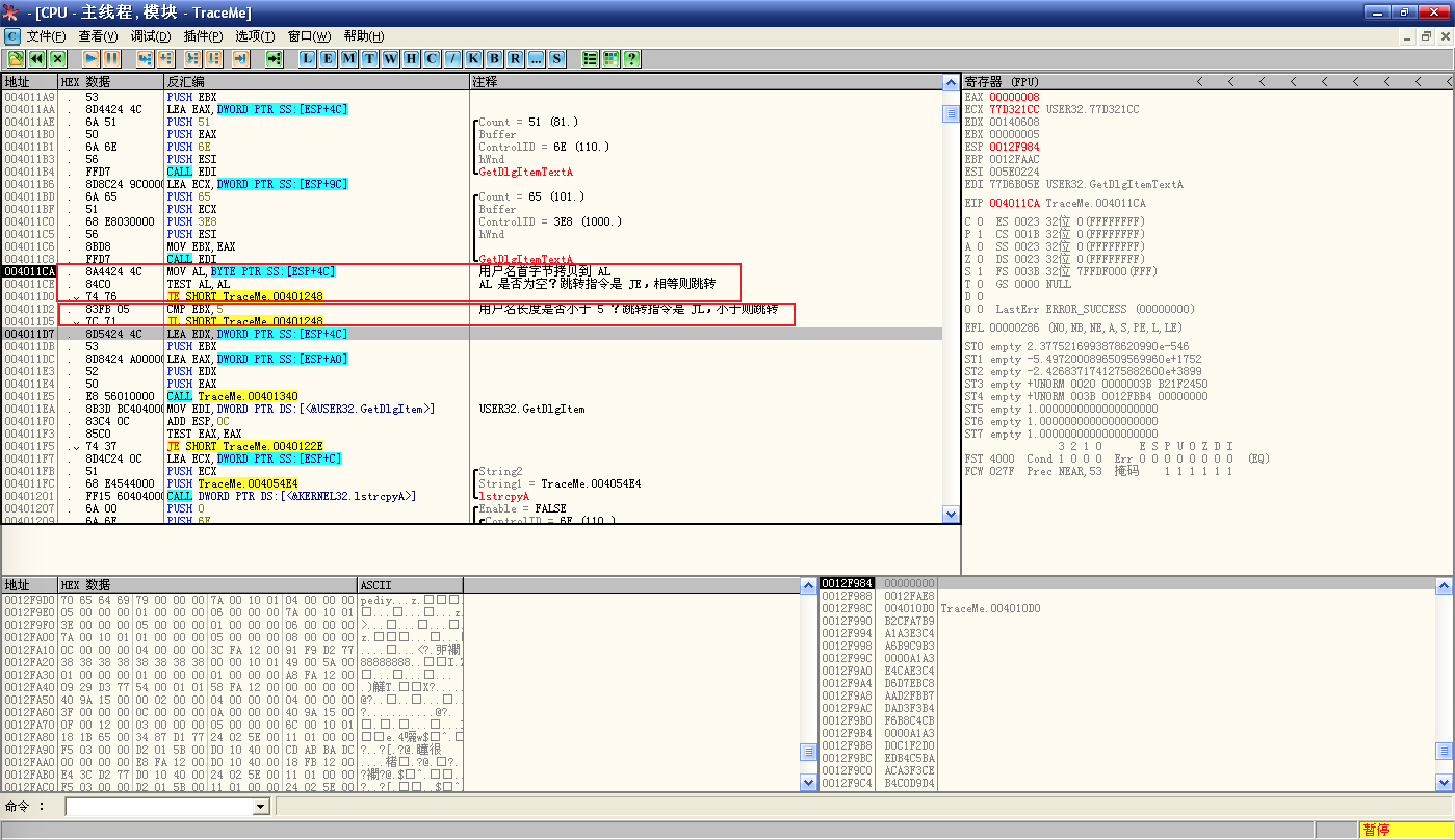
找到了获取输入框文本的
GetDlgItemTextA,设置断点;F9 运行程序后,提示内存非法访问,尝试 Shift + F8 忽略错误后,程序终止:
![Shift + F8]()
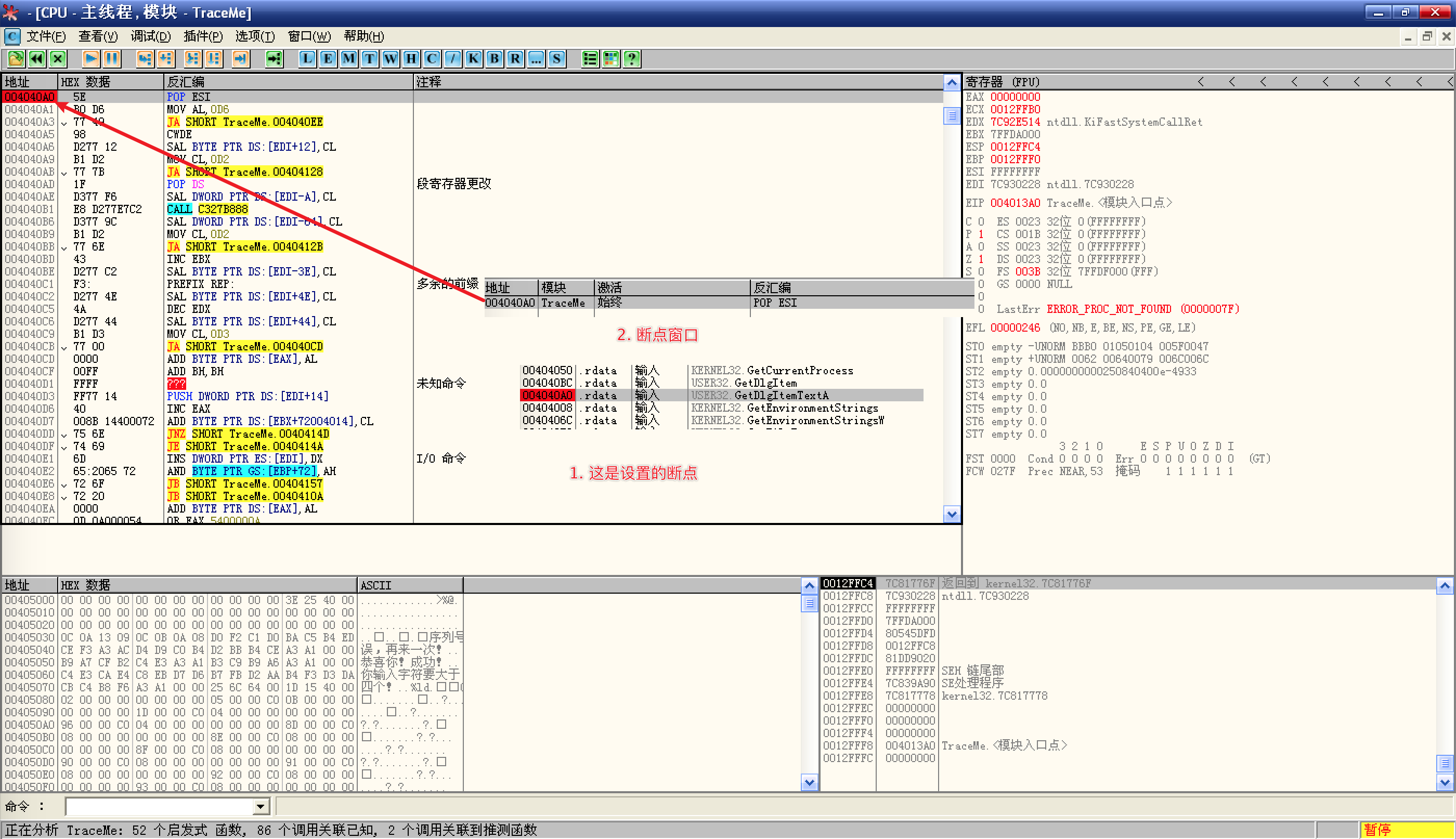
重载程序,Alt + B 来到断点窗口,双击断点到达指令位置,发现断点没有设置在预期位置上,很是奇怪,现在也不明白为什么:
![Alt + B]()
断点处于程序领空而不是系统领空,看来这种方法不行,试试其它方法;
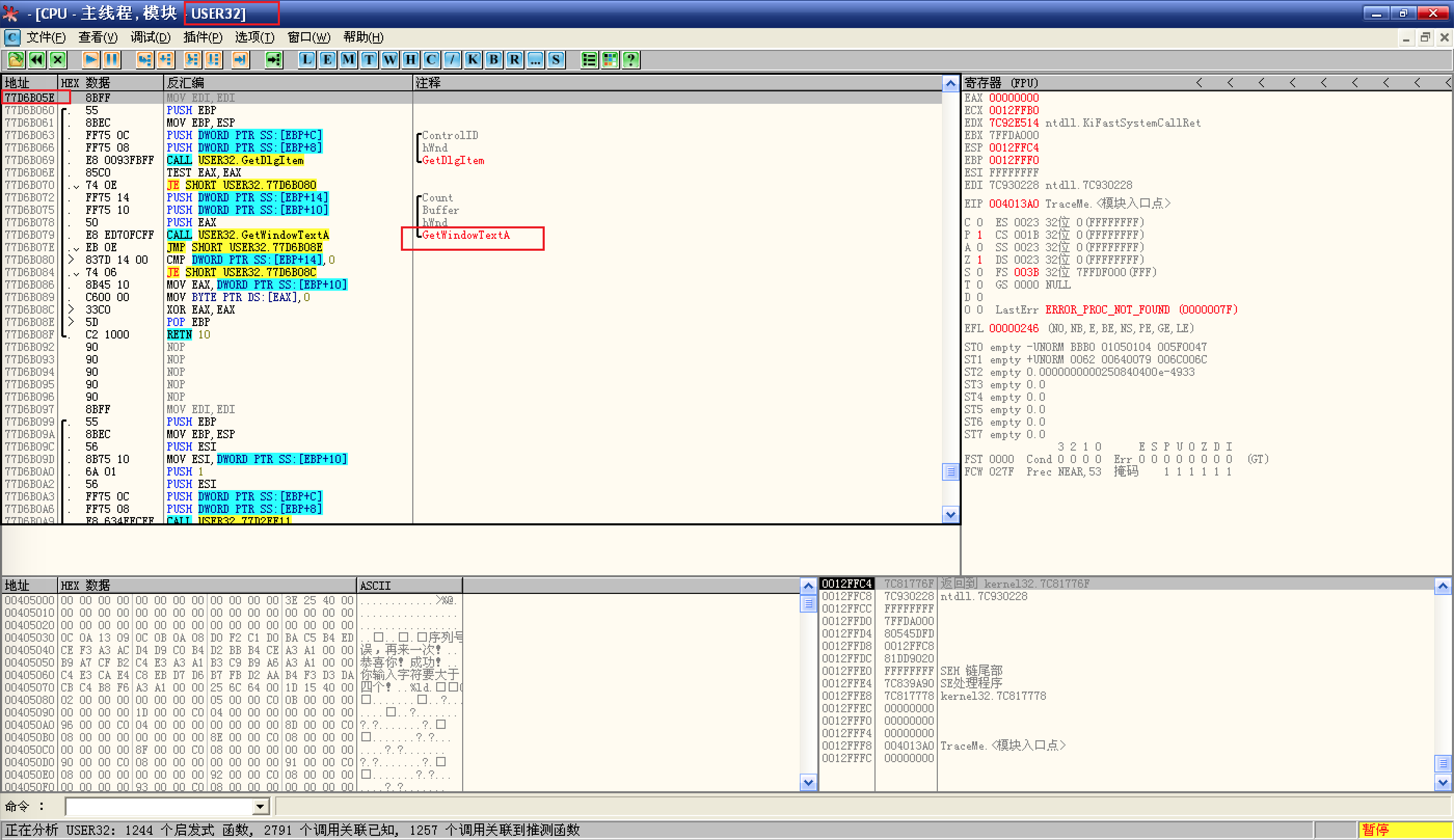
既然在 API 列表可以看到
GetDlgItemTextA,说明程序应该是调用它了,Ctrl + G 输入GetDlgItemTextA,尝试跳转到 API 行首;![Ctrl + G]()
来到此处,无论是指令的地址,OD 的标题栏,还是注释中的信息,都说明这里才是正经八百的
GetDlgItemTextA函数,如果右侧没有注释,可以尝试再次按下 Ctrl + A 分析程序,设置断点,然后运行程序;这次没有错误,输入用户名和序列号,点击 check 之后,程序中断在
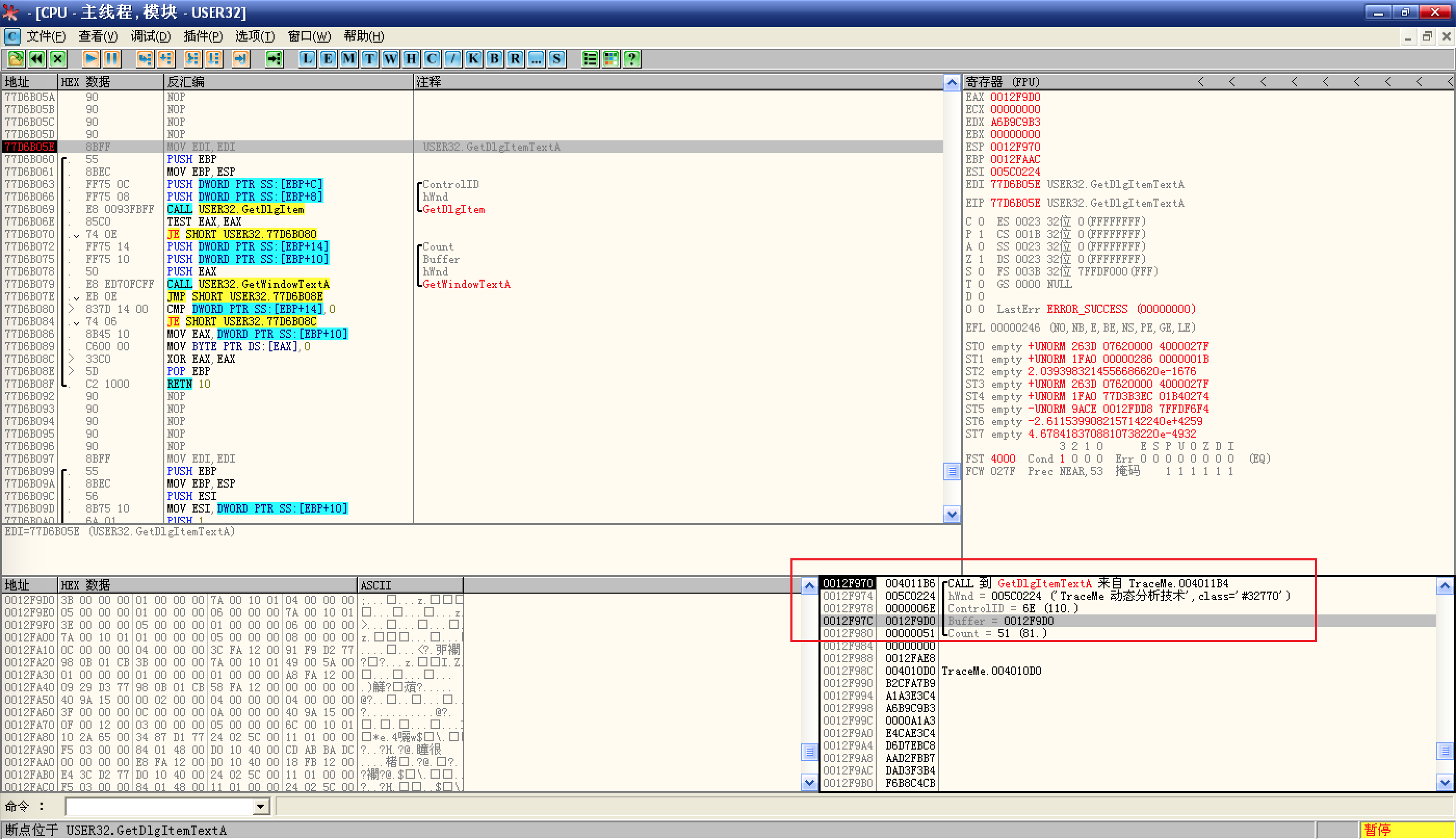
GetDlgItemTextA函数的行首:![栈窗口]()
栈窗口显示了本次调用的详细信息,包括调用位置,最大字符限制,文本缓冲区地址,控件标识以及窗口句柄;
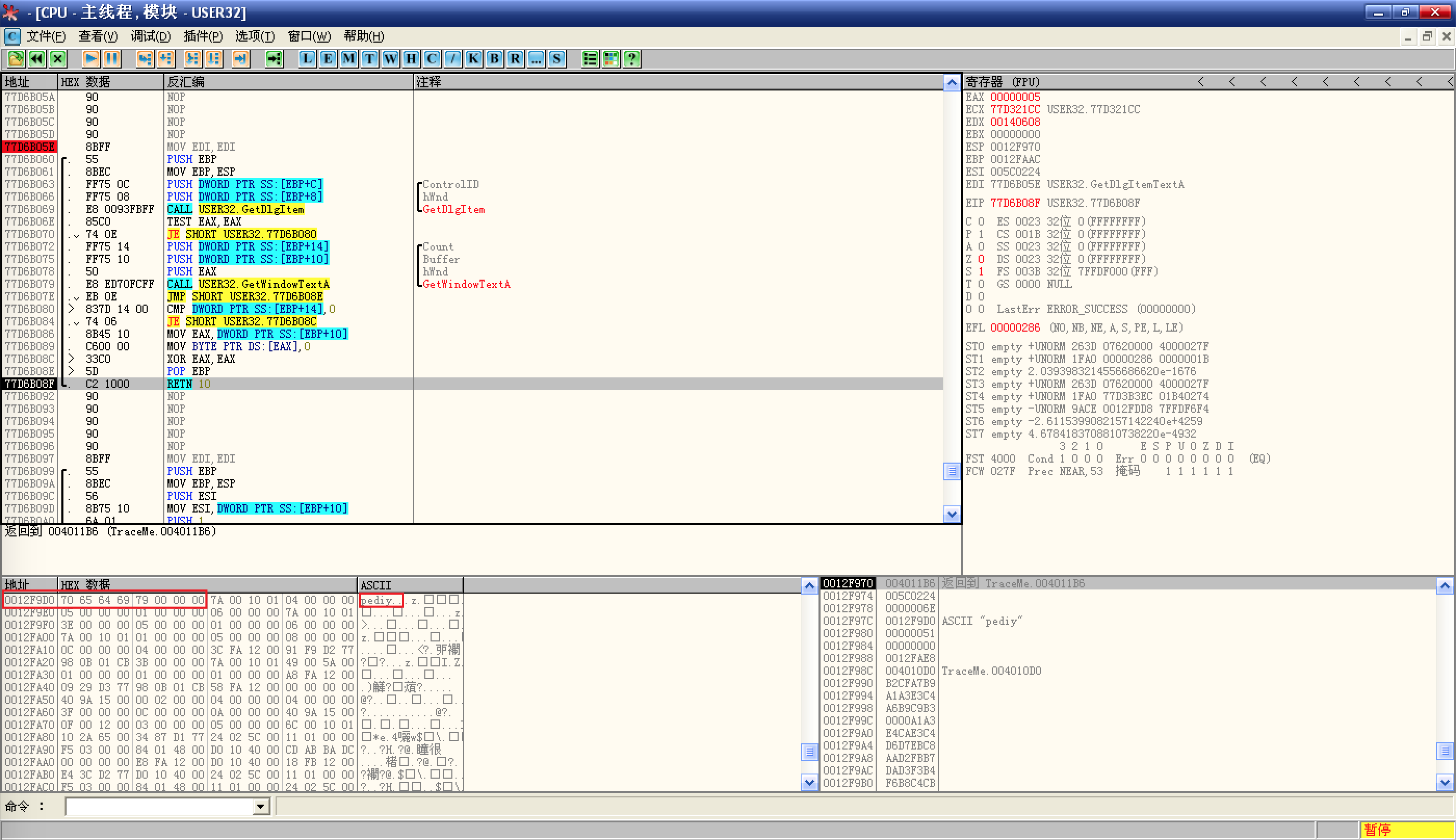
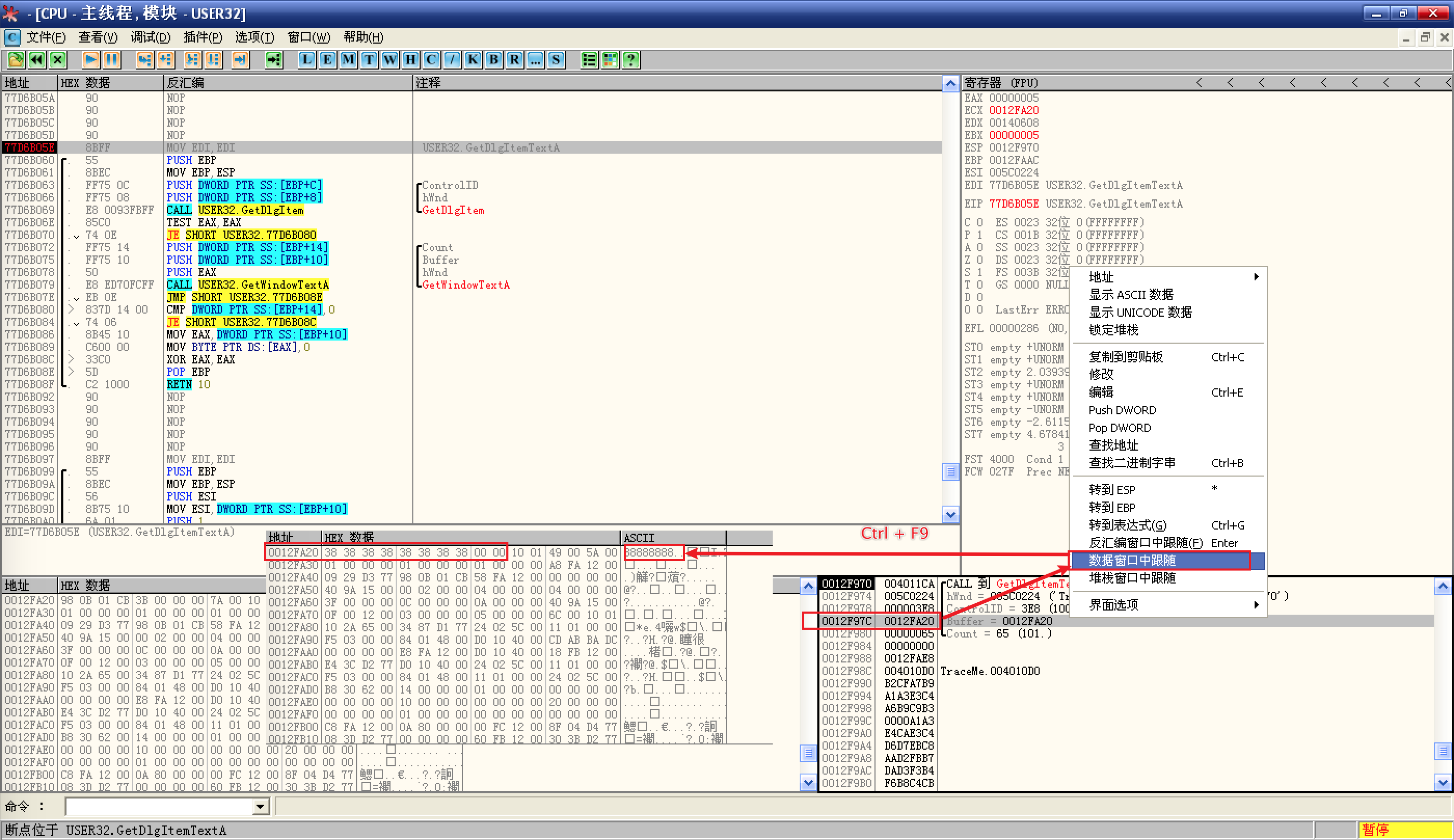
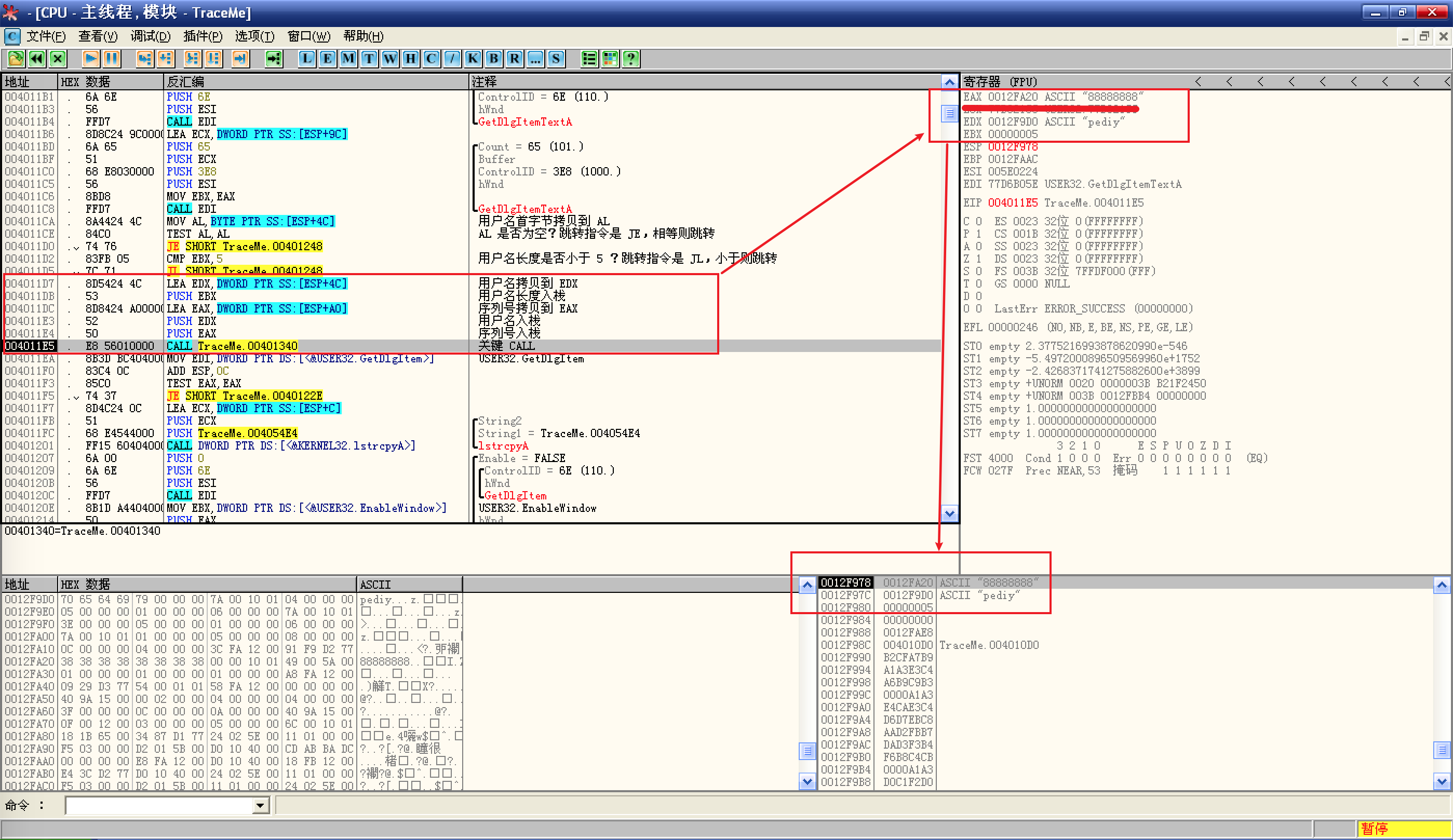
在 Buffer 参数上右键选择数据窗口中跟随,然后 Ctrl + F9 执行
GetDlgItemTextA函数:![执行`GetDlgItemTextA`函数]()
在缓冲区地址中,就看到了输入的用户名;
![密码]()
再次执行同样的步骤,就得到了输入的密码;
看到输入内容不是重点,重点是程序是如何限制用户名必须大于 4 位,以及这样做的含义,还有,程序是如何根据用户名生成序列号的,一探究竟:
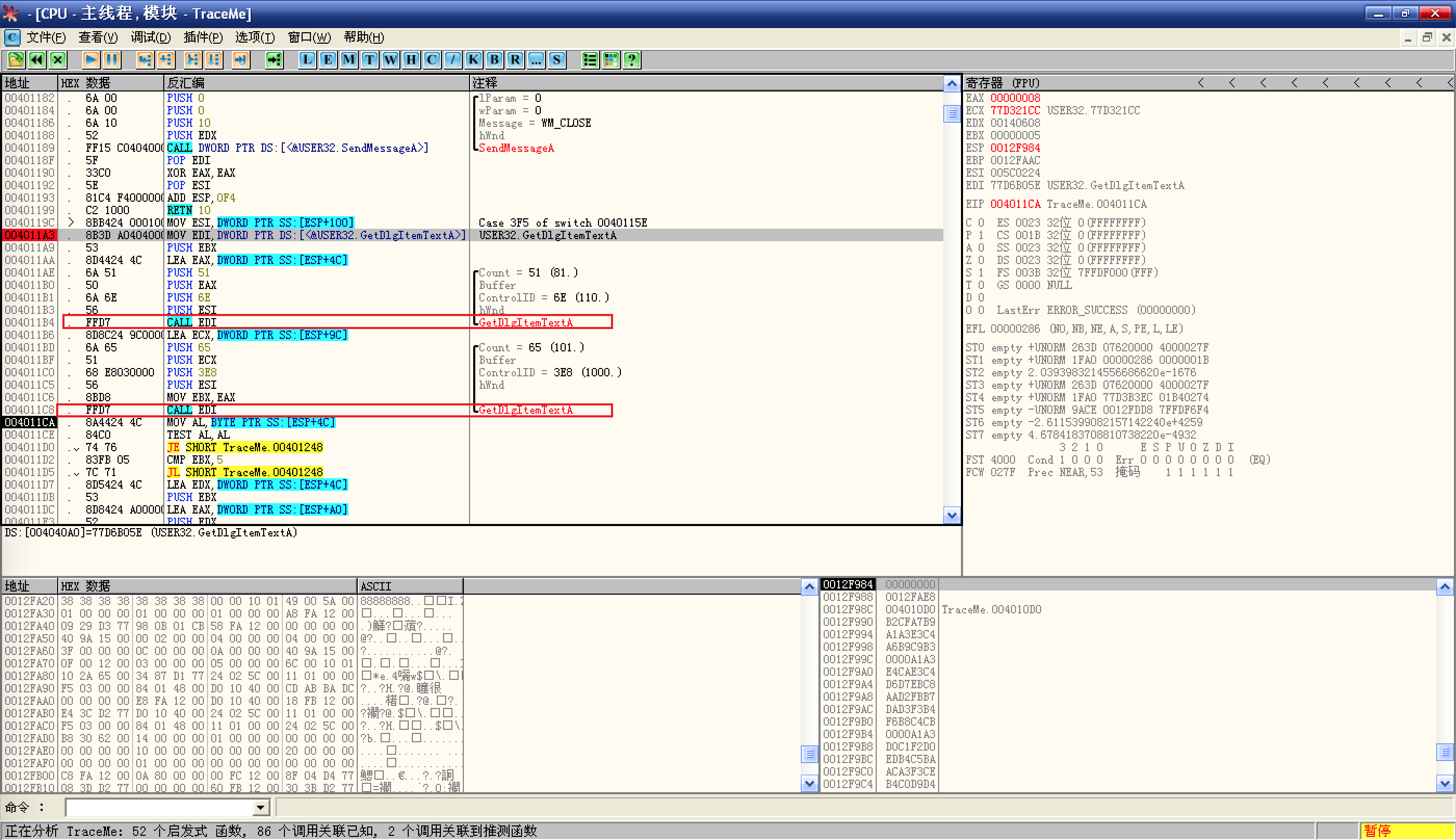
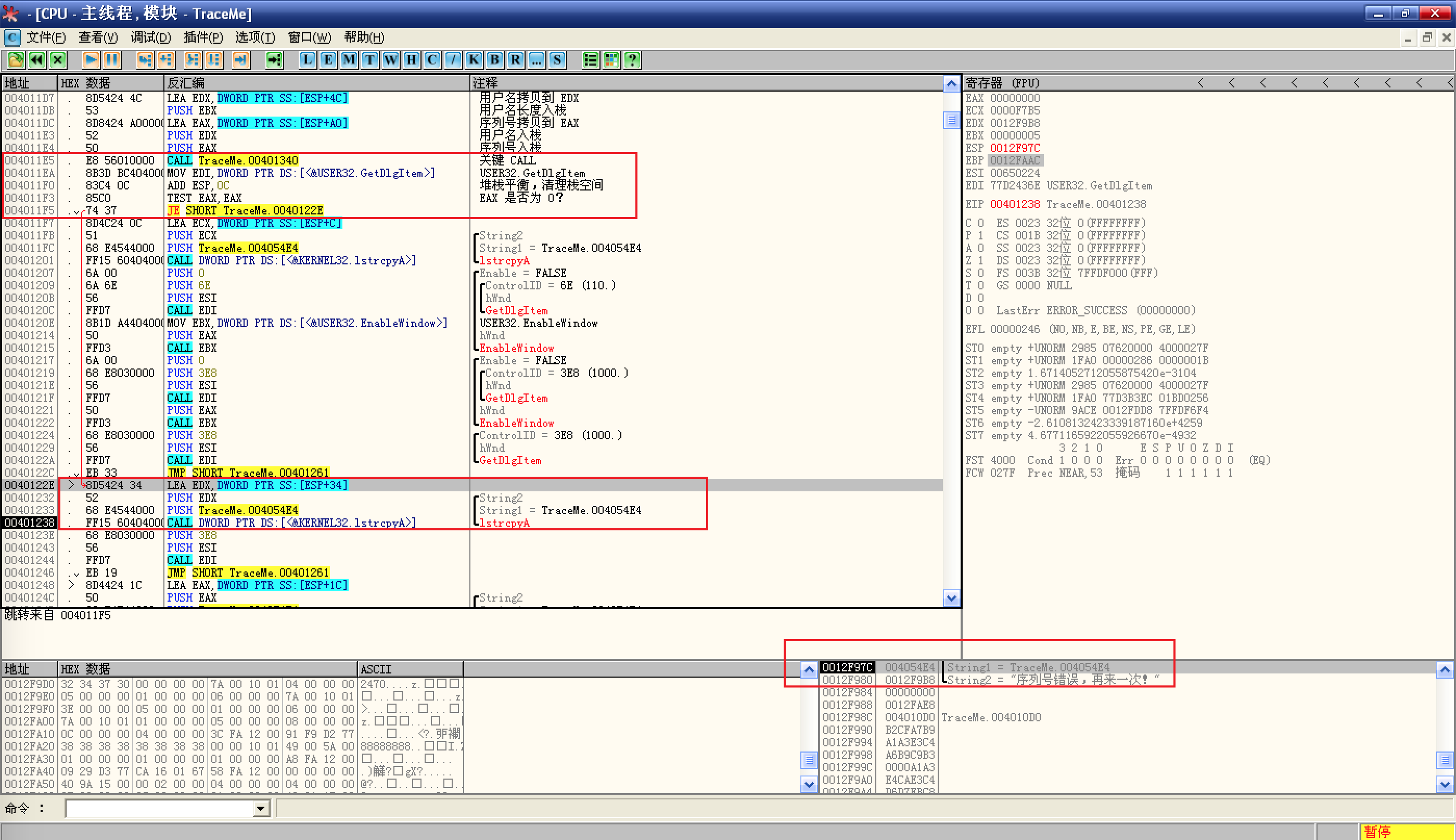
现在,程序已经获取到用户名和序列号了,正常情况下,接下来的步骤就是比较了,我们 F8 跟随到调用
GetDlgItemTextA函数的位置:![F8 跟随到调用]()
可以看到两次都是间接调用
CALL EDI,那么上面这条MOV EDI,DWORD PTR DS:[<&USER32.GetDlgItemTextA>]就是起始位置了,设置断点,然后重载并运行程序;这里,每次都是先把 Buffer(文本缓冲区指针)放入寄存器,然后 PUSH:
![Buffer]()
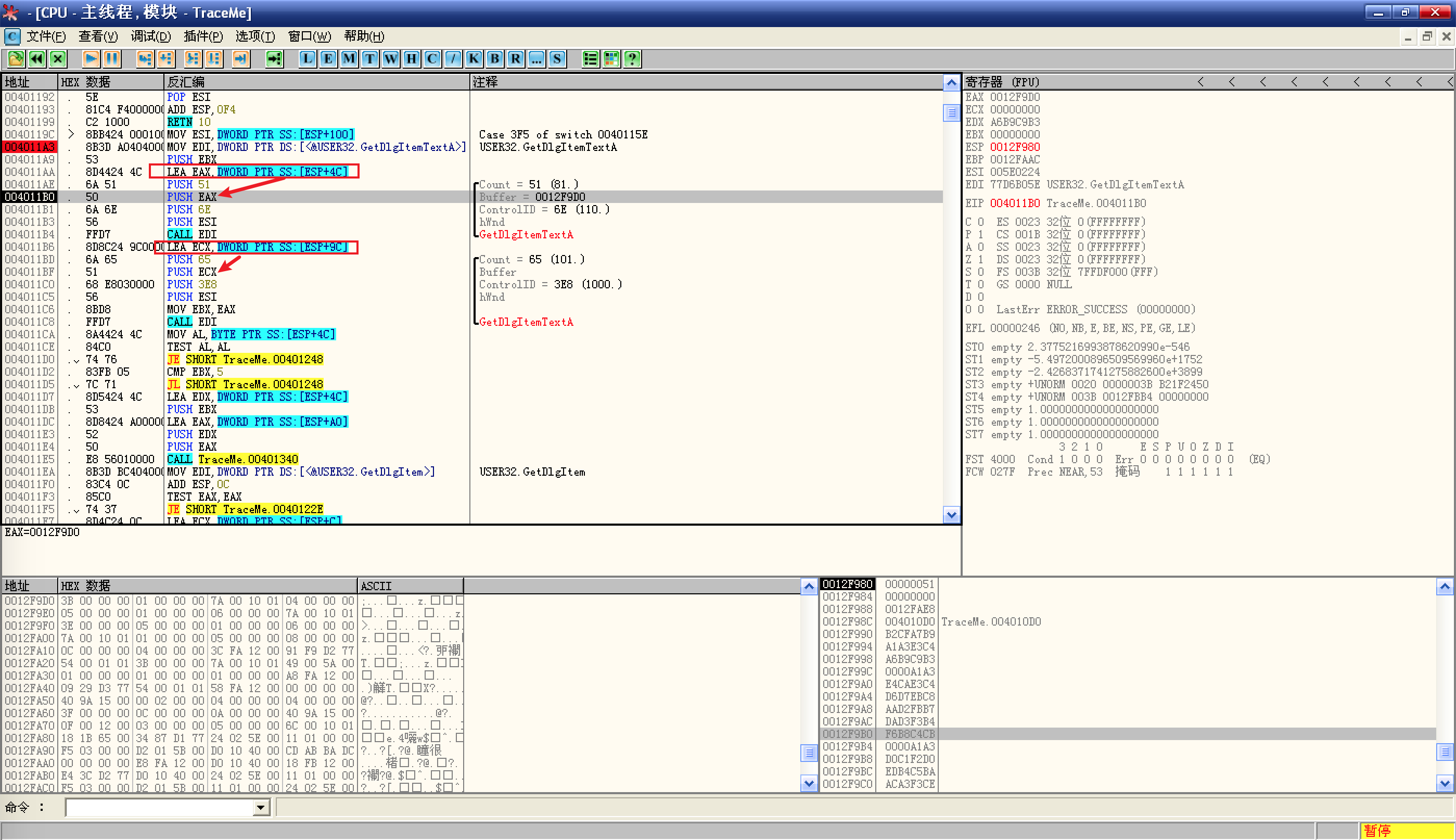
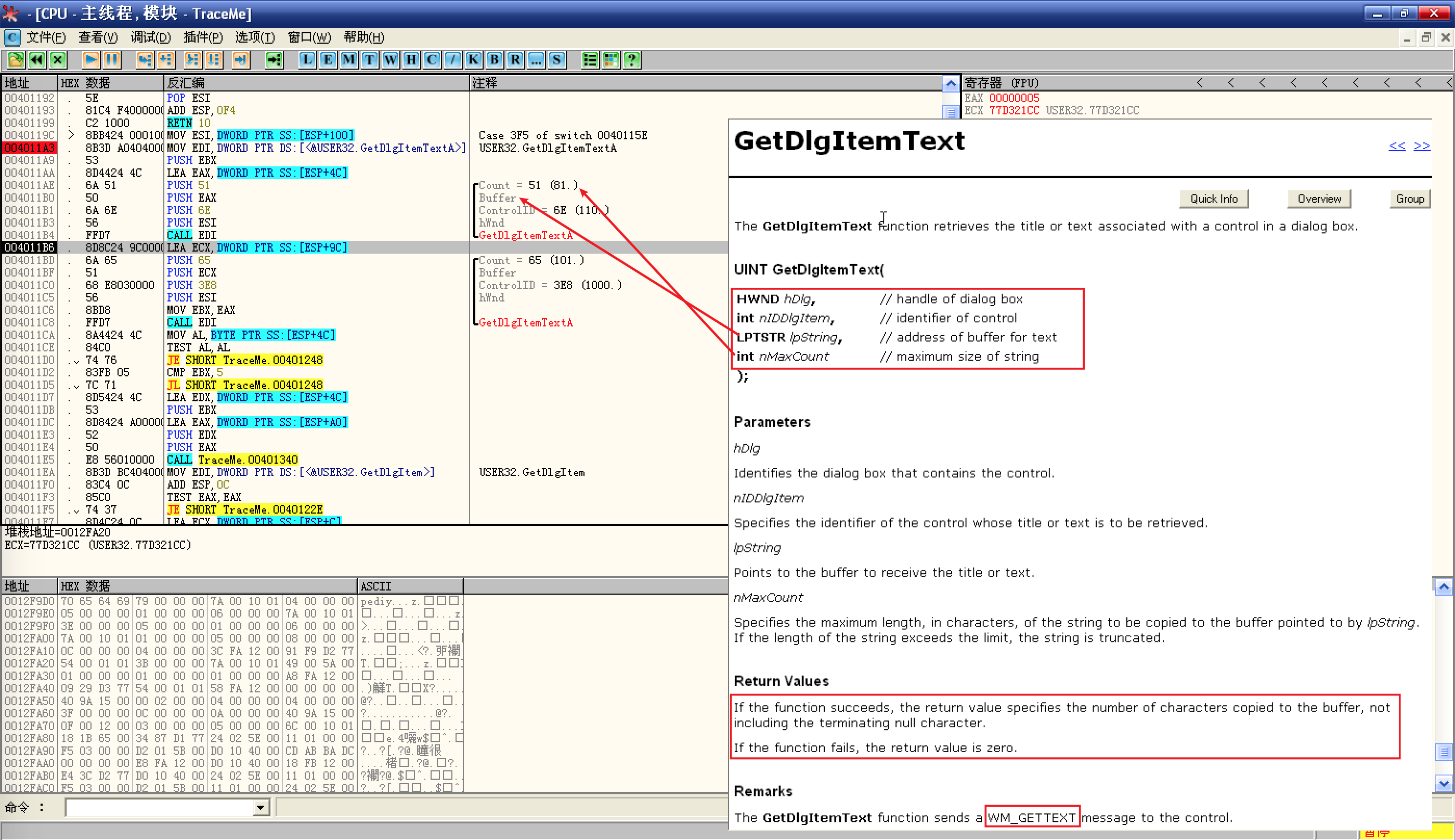
接下来就是调用
GetDlgItemTextA了,先来了解一下这个函数:![先来了解一下这个函数]()
- 首先可以看到,参数入栈的顺序是倒叙的,这是因为 Win32 API 采用 stdcall 调用约定,参数按照从右到左的顺序入栈;
- 再看函数返回值的说明,成功返回字符个数(不包括结尾的 NULL),失败返回 0,函数的返回值默认位于 EAX 中,查看 EAX,确实是用户名的字符个数;
用户名获取完毕,继续执行,同样的方法会获取到输入的序列号;
接下来就是对用户名长度的处理:
![首先是判断用户名是否大于 4 位]()
这里先判断用户名是否为空,然后判断用户名是否大于 4 位,两个跳转的地址相同,应该就是“你输入字符要大于 4 个!”那个弹窗,就不跟了;
需要注意:比较指令需要和接下来的跳转指令一起理解才是正确的;
![关键 CALL]()
这里用户名,用户名长度以及序列号都作为参数传递个了一个 CALL,那么这里很可能就是关键 CALL;
F7 进 CALL 分析:
先上整个分析,然后逐步分析:
![先看整个分析结果]()
首先,下面 👇 的这个跳转是看不懂的:
![下面的这个跳转是看不懂的]()
这里的和 7 比较让人是云里雾里的,不用管它,继续向下分析;
直到来到这里:
![继续向下分析]()
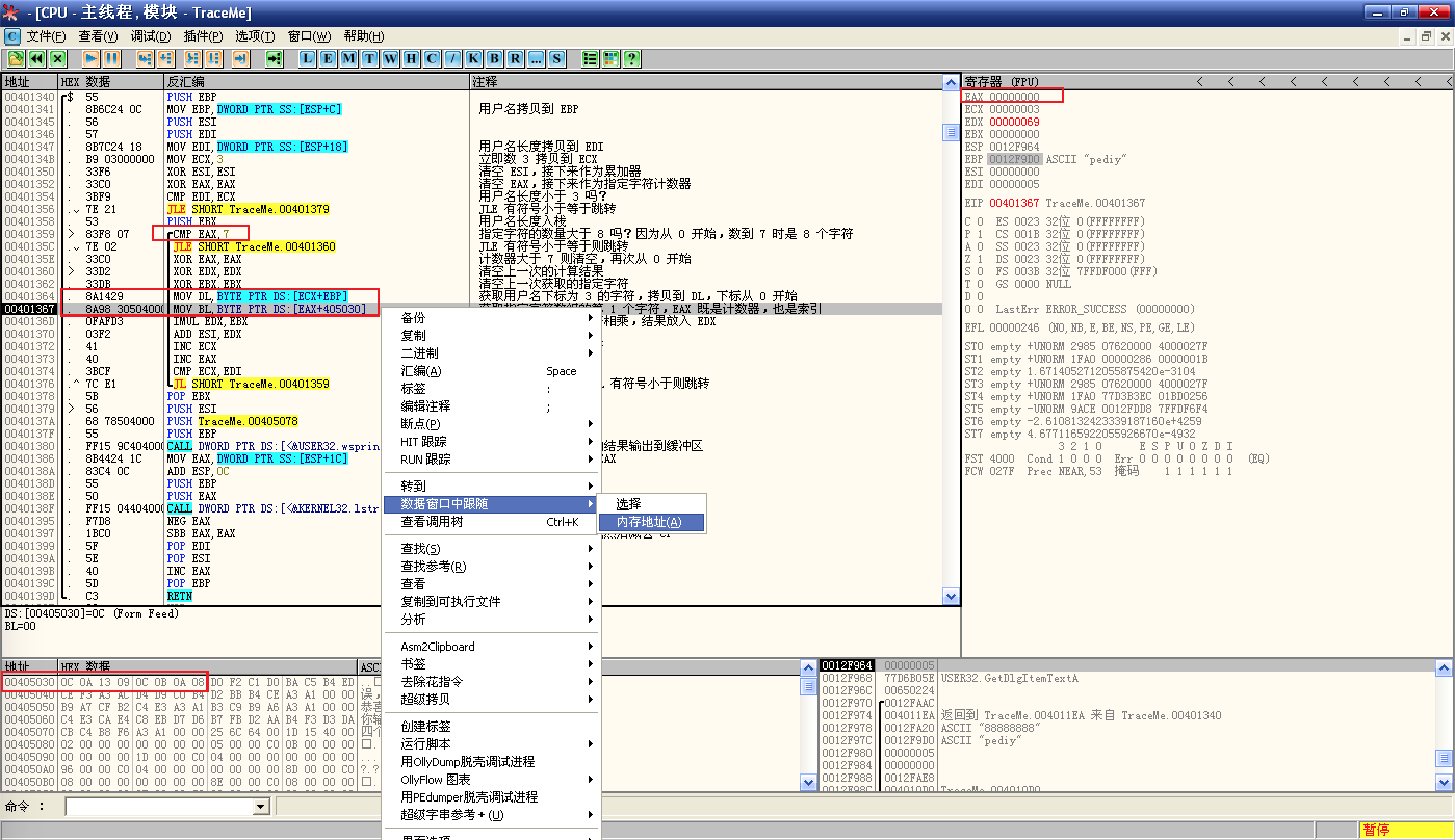
先是
MOV DL,BYTE PTR DS:[ECX+EBP],这里很好理解,ECX 是 3,EBP 是用户名,这条指令的意思是取用户名下标为 3 的字符(BYTE),放入 DL;然后是
MOV BL,BYTE PTR DS:[EAX+405030],理解了上一条语句,这条指令也不难理解,当前 EAX 是 0,这条指令的意思是取 405030 处的第 0 个字符(BYTE)放入 BL,很别扭对不对,因为我们通常数数是从 1 开始的,其实如果 EAX 为 0,这里不好理解,可以先不看下面的语句,让循环再次执行到这里,此时 EAX 为 1,就好理解了,不过取的是第 2 个字符(下标为 1 嘛);理解了这里,然后回想
CMP EAX,7以及JLE SHORT TraceMe.00401360就不难理解了:![就不难理解了]()
这里是一个循环,循环每执行一次,都会取 405030 处下标为 EAX 的字符,然后 EAX 自增 1,并且每次循环开始时,都会将 EAX 和 7 做比较,是不是就可以理解为 405030 处的字符是有限的,如果 EAX 大于 7(因为是 JLE 跳转,小于等于则跳转),则说明 405030 处的字符取完了,此时 JLE 就会跳转失败,从而执行
XOR EAX,EAX让 EAX 置 0,重新从 405030 下标为 0 的字符开始;
上面的循环不好理解,实在理解不了
CMP EAX,7的话,可以输入 4 + 7 = 11,也就是大于 11 个字符的用户名,然后重复执行循环,并且关注 405030 处存放的给定字符,就会进一步理解了;接下来调用了
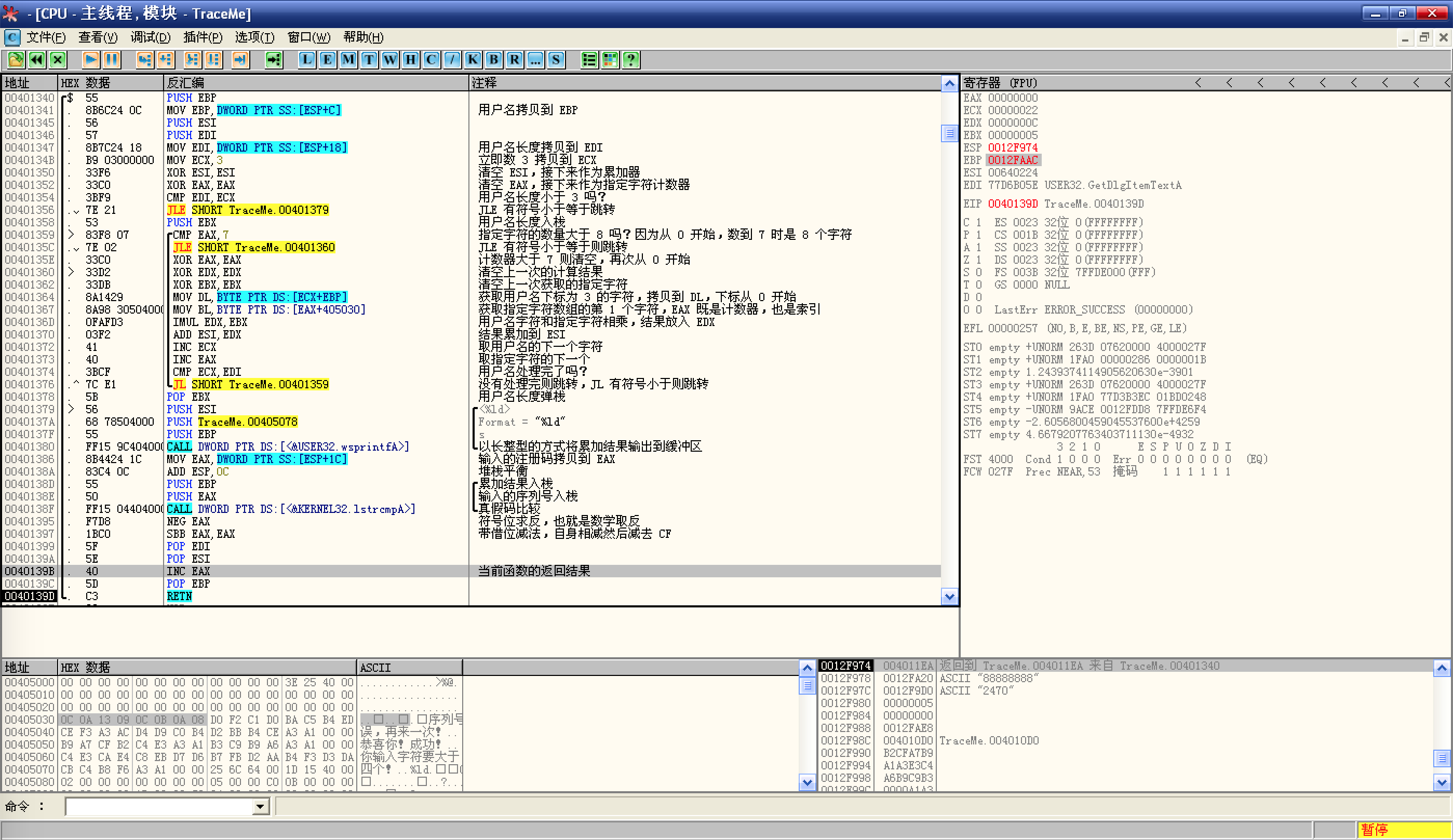
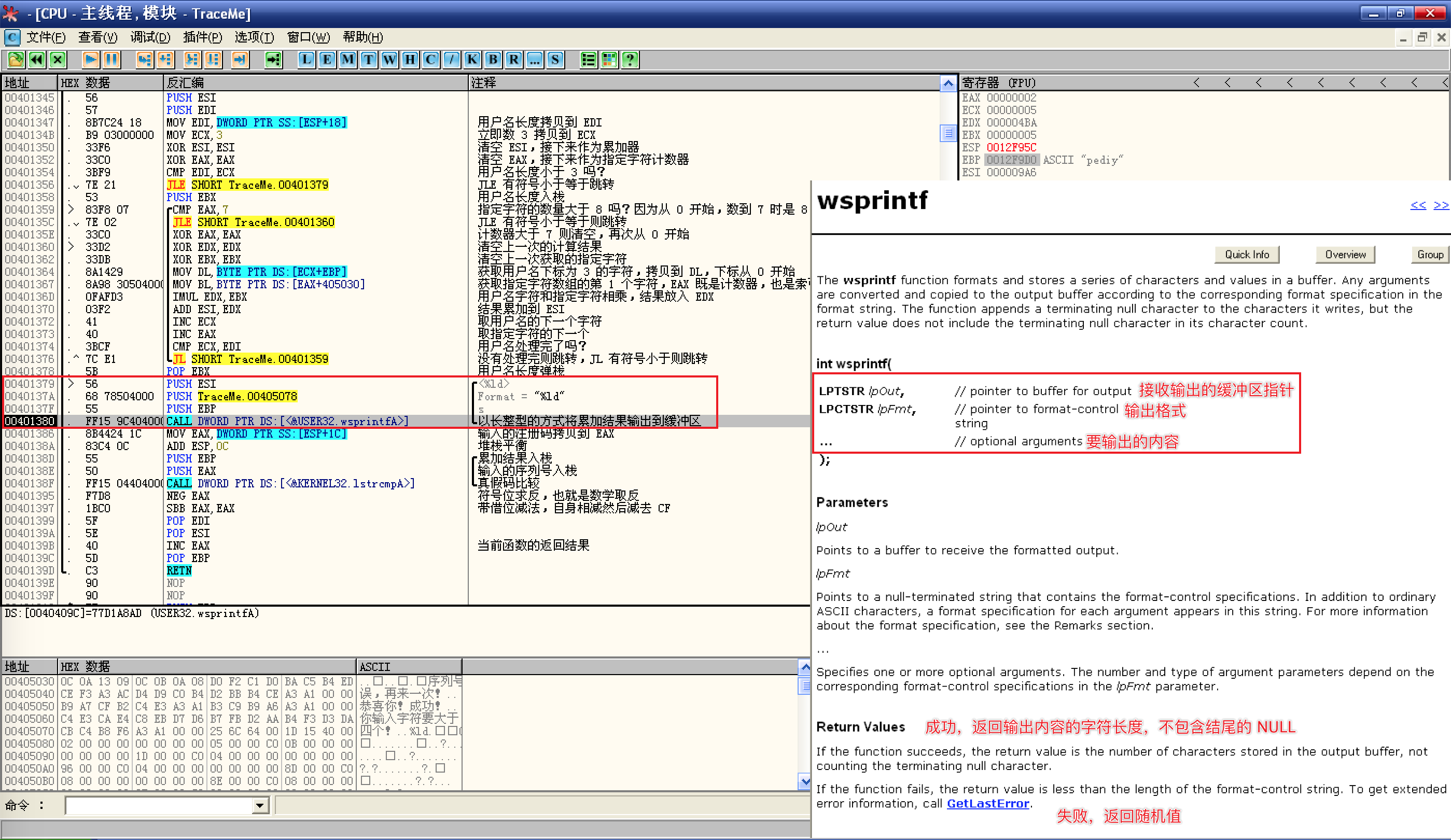
wsprintfA函数:![接下来调用了`wsprintf`函数]()
由于参数是倒序的,所以第 1 个参数是将要输出的内容,而 ESI 存放的是上面循环处理用户名后的结果,接下来是输出格式
%ld,以长整型输出,最后是接收输出的缓冲区指针 EBP,所以,这几条指令的意思是:将处理用户名的最终结果以长整型存储到 EBP 指向的地址;可以在 EBP 上右键选择数据窗口中跟随去查看,计算的结果为 2470(
%ld,10 进制长整型);接下来调用了
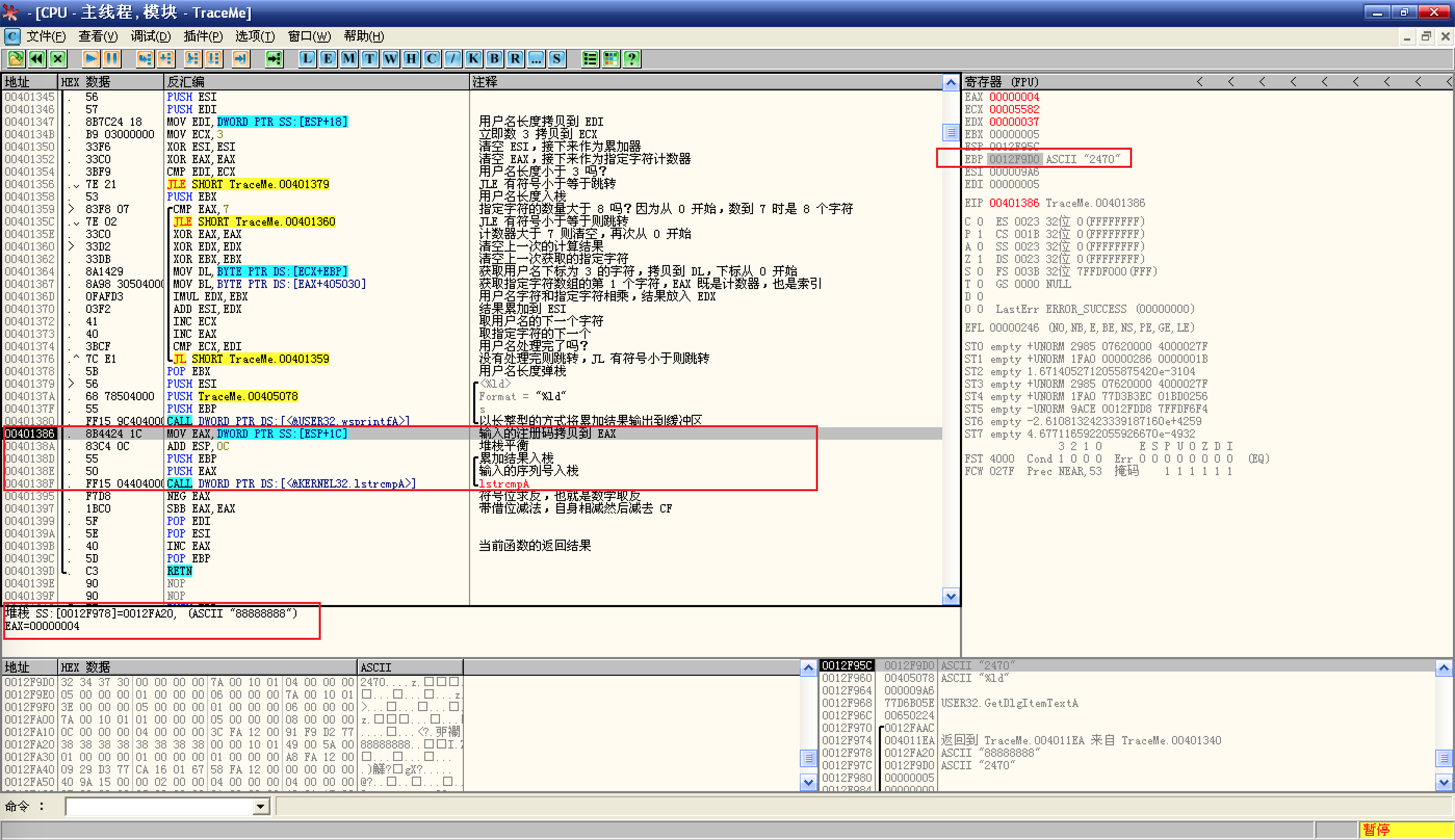
lstrcmpA函数,这里很好理解:![接下来调用了`lstrcmpA`函数]()
从信息面板可以看到,EAX 即将存放的是输入的序列号,而 EBP 存放的则是用户名处理并转为 10 进制之后的值,将它们俩作为参数传递给
lstrcmpA,当然是比较相等了,那么计算的最终结果 2470 就是 pediy 这个用户名对应的注册码了;难点在
lstrcmpA函数执行完毕后下面的指令:常见的处理方式是直接返回
lstrcmpA函数的返回结果,0 表示相等,非 0 表示不相等,而这里使用了不同的方式,查看源码才知道,源码中要返回 true 或 false;![难点在`lstrcmpA`函数执行完毕后下面的指令]()
NEG EAX是取反操作,即 0 - EAX,如,EAX = 5,则NEG EAX的结果为 0 - 5 = -5;同时,
NEG EAX会影响 CF 标志位,EAX 为正数,会产生借位,EAX 为负数,会产生进位,只有 EAX 为 0 时才不会影响 CF 标志位,所以NEG EAX也可以理解为判断 EAX 是否为 0;接下来是
SBB EAX,EAX,SBB 是带借位减法,可以理解为EAX - EAX - CF,首先 EAX - EAX 的结果一定是 0,然后用 0 减去 CF 标志位的值,而这一步的结果受到NEG EAX的影响,因为如果 EAX 自身不为 0,则SBB EAX,EAX的值为 -1;最后是
INC EAX,理解了前面两条指令,这条指令就没什么难度了;所以,从
lstrcmpA函数开始直至函数返回,中间的语句就是判断序列号是否相等:- 如果相等,
NEG EAX不会影响 CF 标志位,SBB EAX,EAX的计算结果为 0,INC EAX后 EAX 为 1,最终返回 1; - 如果不相等,
NEG EAX会使 CF 标志位置 1,SBB EAX,EAX的计算结果为 -1,INC EAX后 EAX 为 0,最终返回 0;
- 如果相等,
关键 CALL 出来后,判断 EAX 是否为 0,然后进行条件跳转:
![关键 CALL 出来后]()
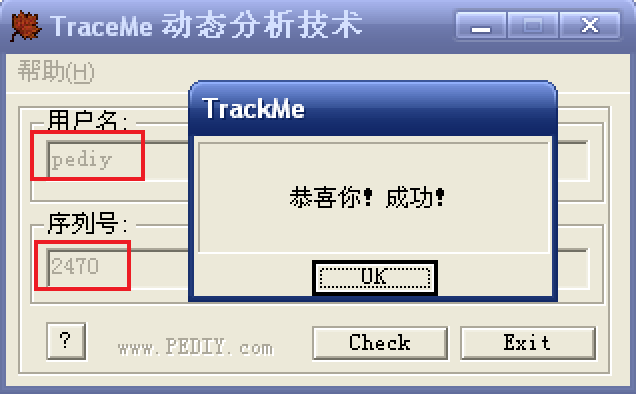
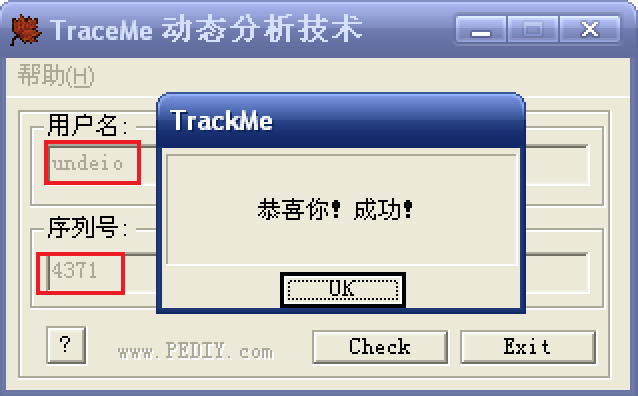
既然找到了用户名对应的序列好,测试一下:
![测试一下]()
完全正确!
最后,说说注册码的规则:
用户名必须大于 4 个字符,也就是大于等于 5;
从用户名的第 4 个字符开始,每次取出 1 个字符,以 16 进制和指定字符相乘,也就说,用户名第 4 个字符对应下标为 0 的字符,当用户名字符多于给定字符时,循环匹配,也就是说,下标为 7 的字符取出后,下一个匹配的是下标为 0 的字符,以此类推;
给定字符如下:0 1 2 3 4 5 6 7 0C 0A 13 09 0C 0B 0A 08 将每次计算的结果累加;
最终结果转换为 10 进制就是用户名对应的注册码;
简单实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
int GenRegCode(char *name, char *table);
int main()
{
char *name = "undeio";
char table[8] = {0xC, 0xA, 0x13, 0x9, 0xC, 0xB, 0xA, 0x8};
printf("%d\n", GenRegCode(name, table));
return 0;
}
int GenRegCode(char *name, char *table)
{
int i, j;
int code;
for (i = 3, j = 0; i < strlen(name); i++, j++)
{
if (j > 7)
j = 0;
code += ((char)name[i]) * table[j];
}
return code;
}以用户名 undeio 为例:
- 首先,undeio 长度大于 4;
- 第 4 个字符为 e, 16 进制为 65,给定字符为 C,65 * 0C = 4BC;
- 第 5 个字符为 i,16 进制为 69,给定字符为 A,69 * 0A = 41A;
- 第 6 个字符为 o, 16 进制为 6F,给定字符为 13,6F * 13 = 83D;
- 最后 4BC + 41A + 83D = 1113,转换为 10 进制后为 4371;
- 测试一下:
![测试一下]()